D-TDNN 论文阅读:Densely Connected Time Delay Neural Network for Speaker Verification
论文提出了一种新的 D-TDNN,与现有的相比,参数量更少;还提出了 D-TDNN 的一种变体;D-TDNN-SS;
D-TDNN
本文提到的相关工作中提到了很多 TDNN 的拓展,可以参阅
Densely Connected Time Delay Neural Network for Speaker Verification
interspeech2020
摘要
In this paper, we propose a novel TDNN-based model, called densely connected TDNN (D-TDNN), by adopting bottleneck layers and dense connectivity. D-TDNN has fewer parameters than existing TDNN-based models.Furthermore, we propose an improved variant of D-TDNN, called D-TDNN-SS, to employ multiple TDNN branches with short-term and longterm contexts. D-TDNN-SS can integrate the information from multiple TDNN branches with a newly designed channel-wise selection mechanism called statistics-and-selection (SS).
- 提出了一种新的 D-TDNN,与现有的相比,参数量更少;
- 还提出了 D-TDNN 的一种变体;D-TDNN-SS;
引言
- 最近又两种 TDNN 模型,E-TDNN 和 F-TDNN;这两种模型相比原始模型都有了较大的提升;
- D-TDNN 参数更少;
- D-TDNN 的变体 D-TDNN-SS;
相关工作
Experiments in [14, 15] show that integrating information from different layers can improve the accuracy of speaker embedding models.
在[ 14、15]中的实验表明,整合不同层的信息可以提高说话人嵌入模型的准确率。
方法
The basic unit of D-TDNN is called D-TDNN layer. D-TDNN layer is similar to the dense layer of DenseNet but the twodimensional convolutional neural network (2D CNN) layers in DenseNet are replaced with FNN and TDNN layers. The advantages of FNN and TDNN layers compared to 2D CNN layers include fewer parameters, less computational cost and a total receptive field in frequency-domain, which are preferred in speaker verification tasks.
Let g denote the output size of the TDNN layer, also called growth rate. We set the output size of the bottleneck layer to be twice of the growth rate, i. e., 2g. Finally, we concatenate the input of the D-TDNN layer and the output of the TDNN layer.
-
将 DenseNet 中的二维卷积神经网络层替换为 FNN 和 TDNN 层;这样参数更少;
-
令g表示TDNN层的输出大小,也称为增长率。我们将瓶颈层的输出大小设置为增长率的两倍,即2g。最后,将D - TDNN层的输入和TDNN层的输出串联起来。有表:
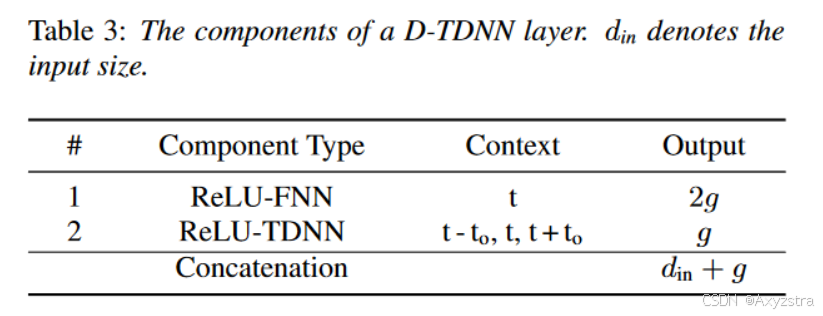
D-TDNN layer
结合表和图,即将 TDNN 输出的绿色和整个 D-TDNN 层的整体输入橙色和红色 connecte 一起;
class DenseTDNNLayer(nn.Module):
def __init__(self,
in_channels,
out_channels,
bn_channels,
kernel_size,
stride=1,
dilation=1,
bias=False,
config_str='batchnorm-relu',
memory_efficient=False):
super(DenseTDNNLayer, self).__init__()
assert kernel_size % 2 == 1, 'Expect equal paddings, but got even kernel size ({})'.format(
kernel_size)
padding = (kernel_size - 1) // 2 * dilation
self.memory_efficient = memory_efficient
self.nonlinear1 = get_nonlinear(config_str, in_channels)
self.linear1 = nn.Conv1d(in_channels, bn_channels, 1, bias=False)
self.nonlinear2 = get_nonlinear(config_str, bn_channels)
self.linear2 = nn.Conv1d(bn_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=bias)
def bn_function(self, x):
return self.linear1(self.nonlinear1(x))
def forward(self, x):
if self.training and self.memory_efficient:
x = cp.checkpoint(self.bn_function, x)
else:
x = self.bn_function(x)
x = self.linear2(self.nonlinear2(x))
return x
- 此处的代码没有进行 connecte,只是输出了经过网络 FNN 和 TDNN 的输出;
D-TDNN Block
We use multiple consecutive D-TDNN layers followed by a FNN layer to construct a D-TDNN block. The FNN layer aims to aggregate multi-stage information from different layers.
使用多个连续的 D-TDNN layer 和 FNN 来构建 D-TDNN Block;
class DenseTDNNBlock(nn.ModuleList):
def __init__(self,
num_layers,
in_channels,
out_channels,
bn_channels,
kernel_size,
stride=1,
dilation=1,
bias=False,
config_str='batchnorm-relu',
memory_efficient=False):
super(DenseTDNNBlock, self).__init__()
for i in range(num_layers):
layer = DenseTDNNLayer(in_channels=in_channels + i * out_channels,
out_channels=out_channels,
bn_channels=bn_channels,
kernel_size=kernel_size,
stride=stride,
dilation=dilation,
bias=bias,
config_str=config_str,
memory_efficient=memory_efficient)
self.add_module('tdnnd%d' % (i + 1), layer)
def forward(self, x):
for layer in self:
x = torch.cat([x, layer(x)], dim=1)
return x
x = torch.cat([x, layer(x)], dim=1)才完整的实现了 D-TDNN,即将当前层的输出和当前层的输入 connected 一起;
D-TDNN 网络
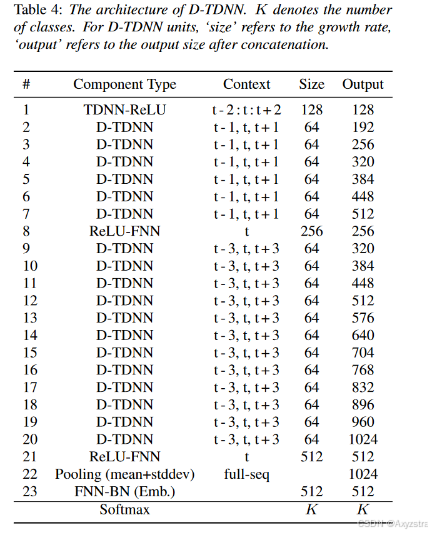
查看添加 D-TDNNBlock 的代码片段
for i, (num_layers, kernel_size,
dilation) in enumerate(zip((6, 12), (3, 3), (1, 3))):
block = DenseTDNNBlock(num_layers=num_layers,
in_channels=channels,
out_channels=growth_rate,
bn_channels=bn_size * growth_rate,
kernel_size=kernel_size,
dilation=dilation,
config_str=config_str,
memory_efficient=memory_efficient)
self.xvector.add_module('block%d' % (i + 1), block)
channels = channels + num_layers * growth_rate
self.xvector.add_module(
'transit%d' % (i + 1),
TransitLayer(channels,
channels // 2,
bias=False,
config_str=config_str))
channels //= 2
for i, (num_layers, kernel_size,
dilation) in enumerate(zip((6, 12), (3, 3), (1, 3))):
enumerate函数可以给可迭代的对象添加一个索引计数,返回的是一个枚举对象,其中包含了索引和对应的值。zip函数接受一系列可迭代的对象作为参数,并将它们打包成一个个元组,然后返回由这些元组组成的列表或迭代器。
在这段代码中,zip 函数接收三个列表 (6, 12)、(3, 3) 和 (1, 3) 作为参数,并将它们打包成元组的列表:
[(6, 3, 1),
(12, 3, 3)]
然后,enumerate 函数被用来遍历这个列表,并为每个元素添加一个索引。假设我们把这个列表赋值给一个变量 params,那么 enumerate(params) 的结果是:
[(0, (6, 3, 1)),
(1, (12, 3, 3))]
即 6 层卷积核大小为 3 daliation 为 1 的 D-TDNN;
12 层卷积核大小为 3 daliation 为 3 的 D-TDNN;
代码和表格中一致;
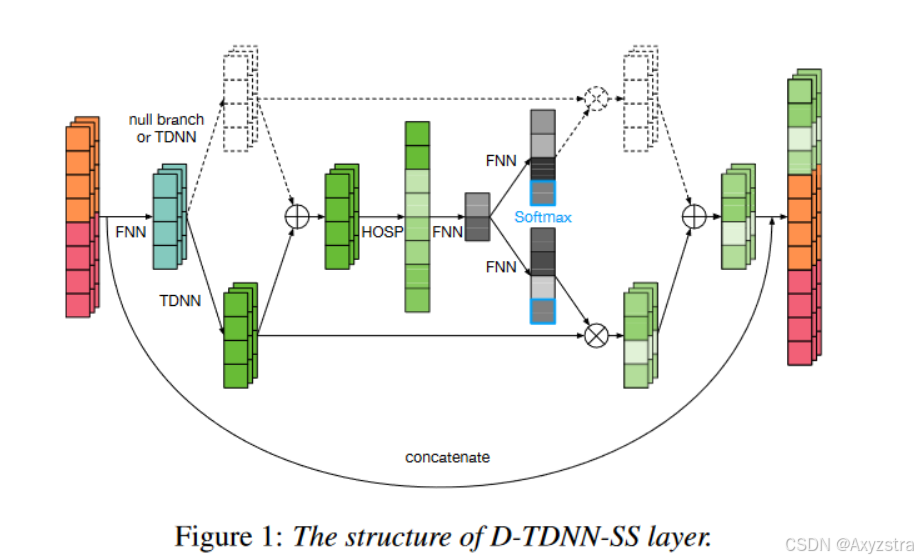
D-TDNN-SS
-
分成多个 TDNN 分支;
-
每个分支上的核大小核帧偏移量是不同的;
-
HOSP 对均值方差等进行计算:
h ~ t = ∑ i = 1 B h t i , \tilde{\mathbf{h}}_t=\sum_{i=1}^B\mathbf{h}_t^i, h~t=i=1∑Bhti,
其中B表示分支数,htERC表示第t帧第i个分支的特征向量,C表示通道数。
μ = 1 T ∑ t = 1 T h ~ t , σ = 1 T ∑ t = 1 T h ~ t ⊙ h ~ t − μ ⊙ μ , s = 1 T ∑ t = 1 T ( h ~ t − μ σ ) 3 , k = 1 T ∑ t = 1 T ( h ~ t − μ σ ) 4 , \begin{aligned} &\boldsymbol{\mu}=\frac{1}{T}\sum_{t=1}^{T}\tilde{\mathbf{h}}_{t}, \\ & \sigma=\sqrt{\frac{1}{T}\sum_{t=1}^{T}\tilde{\mathbf{h}}_{t}\odot\tilde{\mathbf{h}}_{t}-\boldsymbol{\mu}\odot\boldsymbol{\mu},} \\ &\mathbf{s}=\frac{1}{T}\sum_{t=1}^{T}\left(\frac{\tilde{\mathbf{h}}_{t}-\boldsymbol{\mu}}{\sigma}\right)^{3}, \\ &\mathbf{k}=\frac{1}{T}\sum_{t=1}^{T}\left(\frac{\tilde{\mathbf{h}}_{t}-\boldsymbol{\mu}}{\sigma}\right)^{4}, \end{aligned} μ=T1t=1∑Th~t,σ=T1t=1∑Th~t⊙h~t−μ⊙μ,s=T1t=1∑T(σh~t−μ)3,k=T1t=1∑T(σh~t−μ)4, -
第一个 FNN 层进行一个聚合:
z = U ⊤ [ μ , σ , s , k ] + p , \mathbf{z}=\mathbf{U}^\top[\mu,\sigma,\mathbf{s},\mathbf{k}]+\mathbf{p}, z=U⊤[μ,σ,s,k]+p, -
接下来每个分支有一个 FNN,作如下计算:
b i = V i ⊤ z + q i , a c i = e b c i ∑ j = 1 B e b c j , h t = ∑ i = 1 B a i ⊙ h t i , \begin{gathered} \mathbf{b}^{i} =\mathbf{V}^i{}^\top\mathbf{z}+\mathbf{q}^i, \\ a_{c}^{i} =\frac{e^{b_c^i}}{\sum_{j=1}^Be^{b_c^j}}, \\ \mathbf{h}_t =\sum_{i=1}^B\mathbf{a}^i\odot\mathbf{h}_t^i, \end{gathered} bi=Vi⊤z+qi,aci=∑j=1Bebcjebci,ht=i=1∑Bai⊙hti, -
通过以上措施,可以评估不同分支的重要性,是一种注意力的思想;
结果
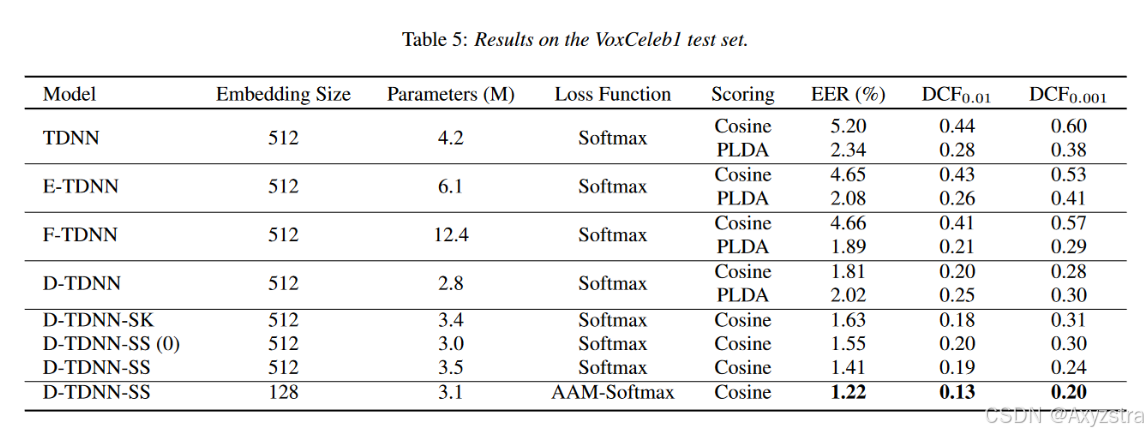
- D-TDNN-SS 包含两个分支,帧偏移量分别为 1 或 3;
- D-TDNN-SS(0) 是包含一个空分支;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)