Spring AI官方文档怎么看,教你入门Spring AI
6年java程序员转大模型开发了,本文将教大家怎么阅读Spring AI官方文档,让大家少走弯路
Spring AI官方文档如何看
1.1 入口
Spring AI官网:https://spring.io/projects/spring-ai
很多人不知道SpringAI官网怎么看,按照我下面的步骤
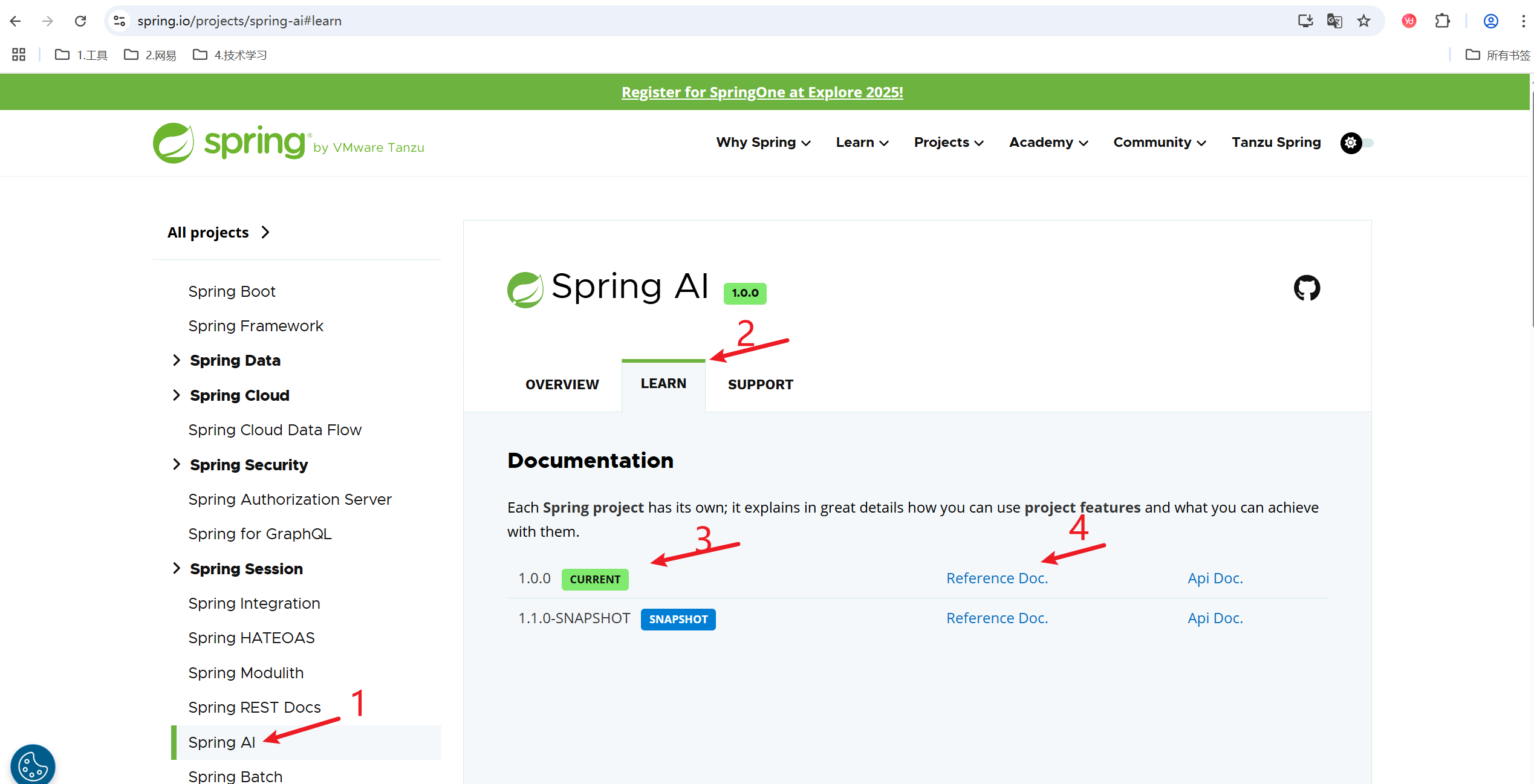
步骤1:Spring有很多工程,Spring AI只是其中一个,所以找到Spring AI的入口
步骤2:learn表示学习,左边的overview是概述,只是简单地介绍了Spring AI有哪些功能
步骤3:版本列表。1.0.0是当前最新版,也是正式版,而下面的的1.1.0-SNAPSHOT是开发版,我们看文档肯定是要看稳定版的
步骤4:Reference Doc表示参考文档,这就是Spring AI文档的入口
1.2 向量数据库
比如我要看向量数据库这块,比如我要使用ES作为向量数据库,需要怎么做?比如需要引入什么依赖,需要配置哪些东西
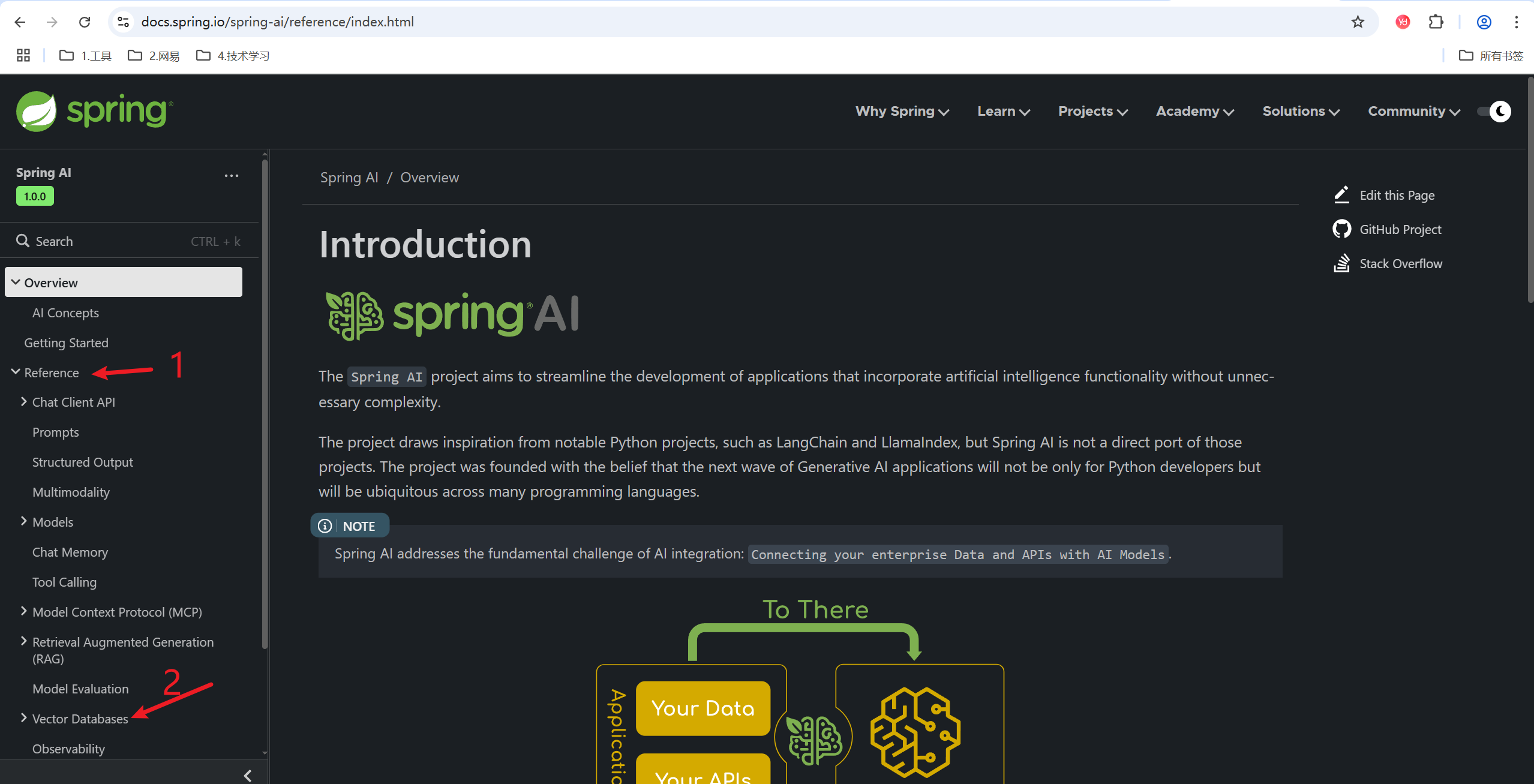
步骤1:展开
步骤2:Vector Databases就是向量数据库,点一下展开
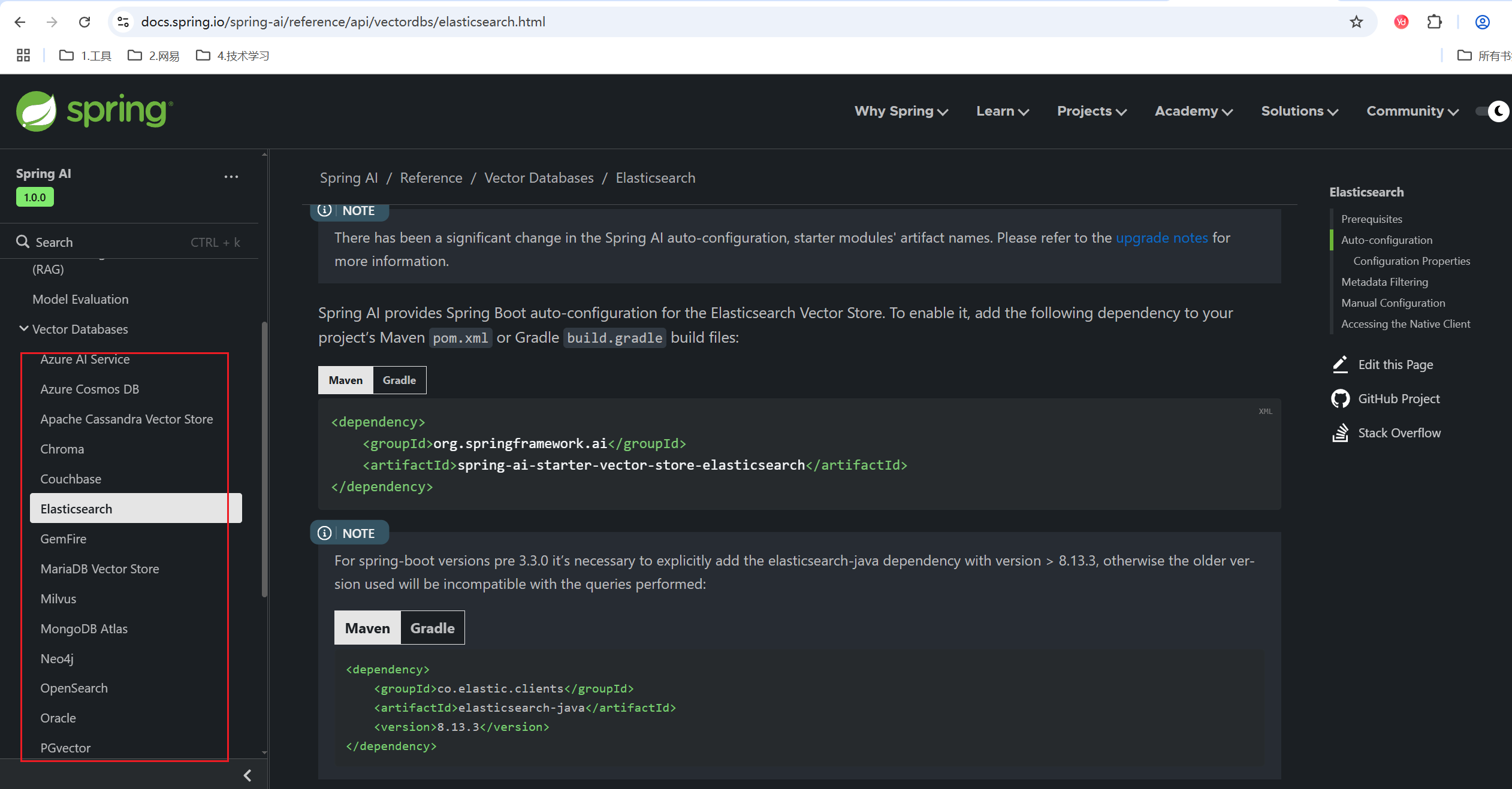
可以看到,左侧有很多向量数据库,比如ES、MongoDB、Oracle等。点击Elasticsearch
除了点击Elasticsearch,还可以点击 VectorStore Implementations,表示向量数据库实现
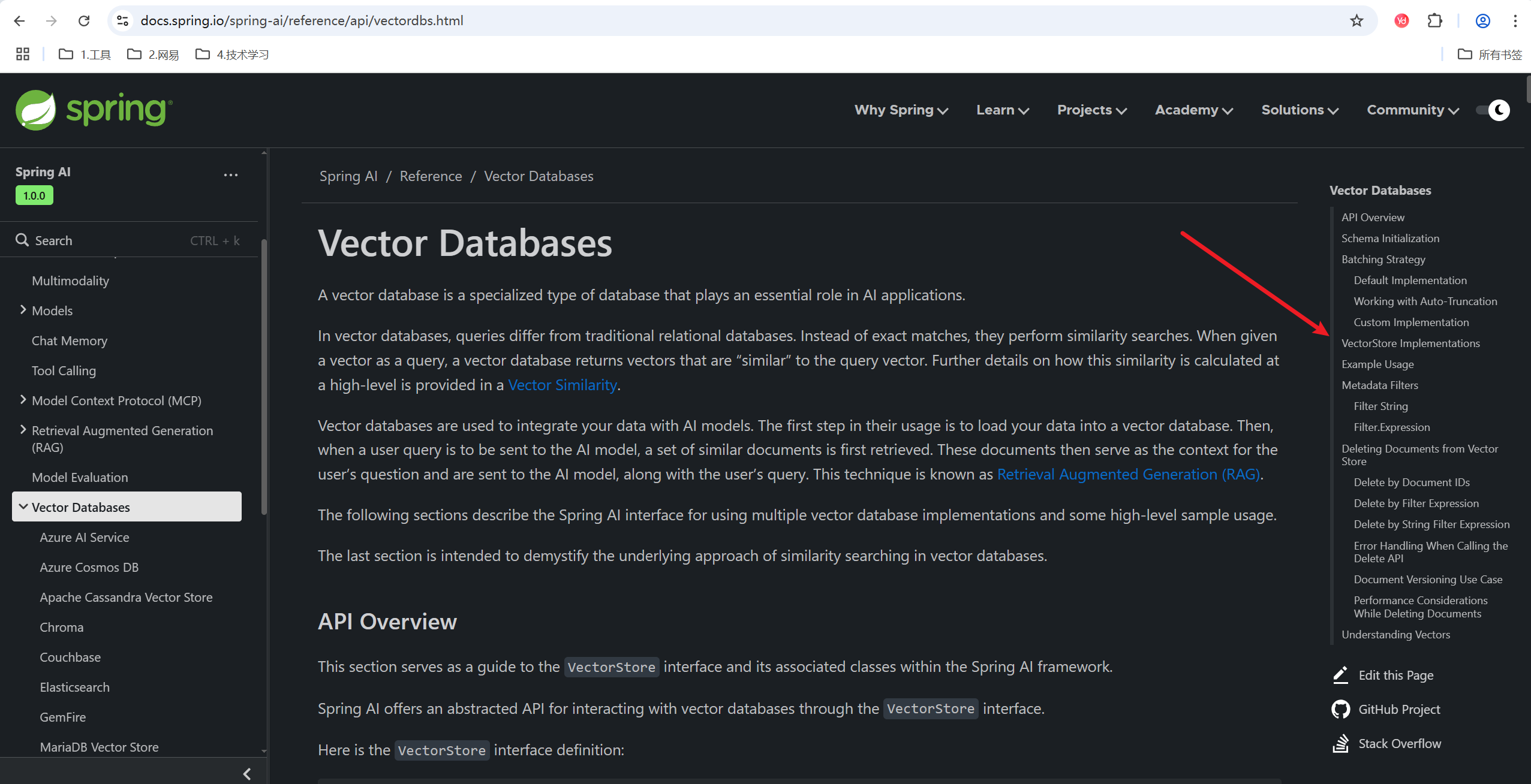
点了之后,就来到如下页面,说明SpringAI向量数据库的实现有下图中显示的那么多
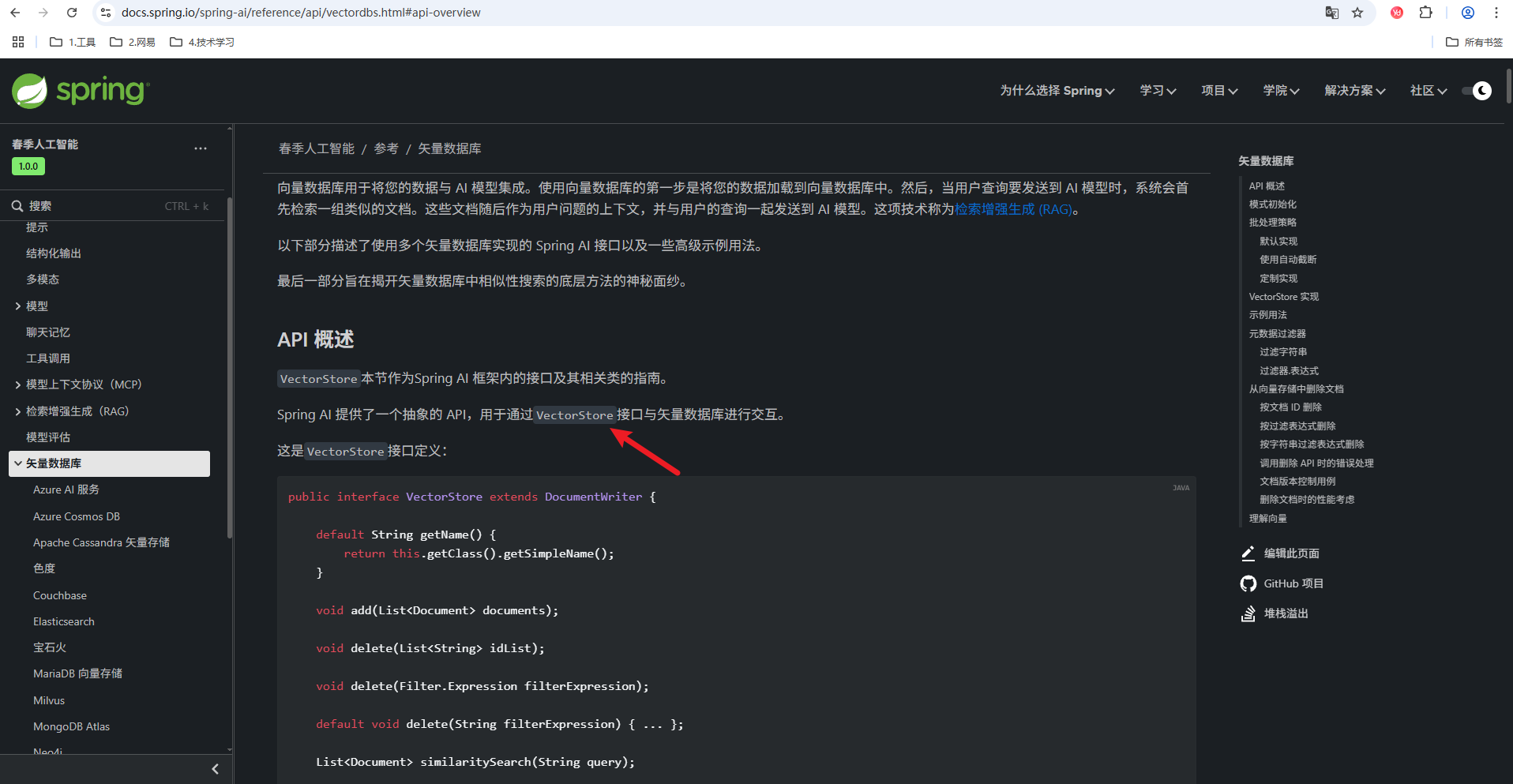
注意,文档中明确说明,这些向量数据库都是实现VectorStore接口
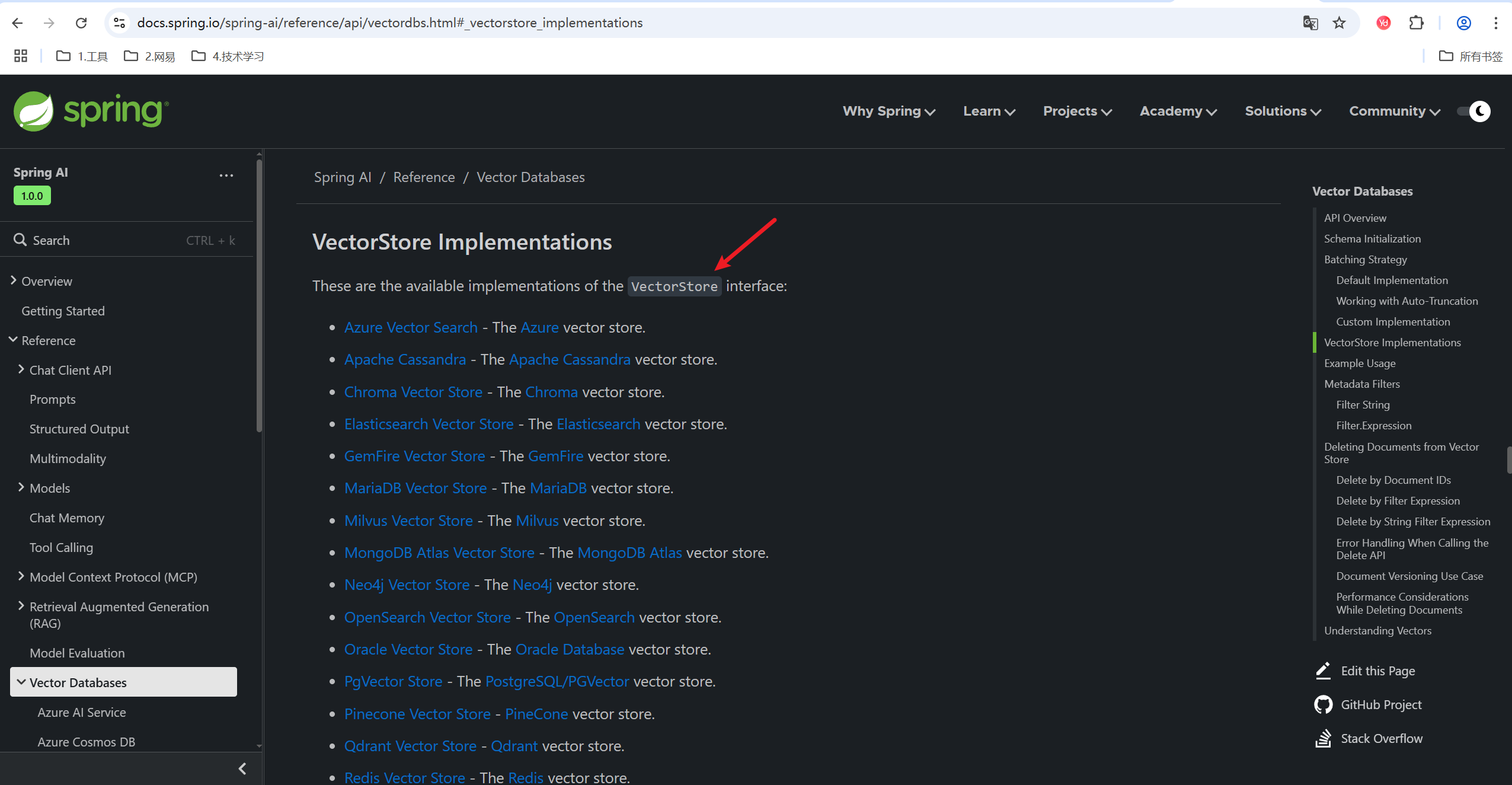
然后再点击Elasticsearch Vector Store,来到ES向量数据库
网页翻译成英文,可以看到,文档中明确说,使用ES作为向量数据库,需要引入spring-ai-starter-vector-store-elasticsearch这个依赖
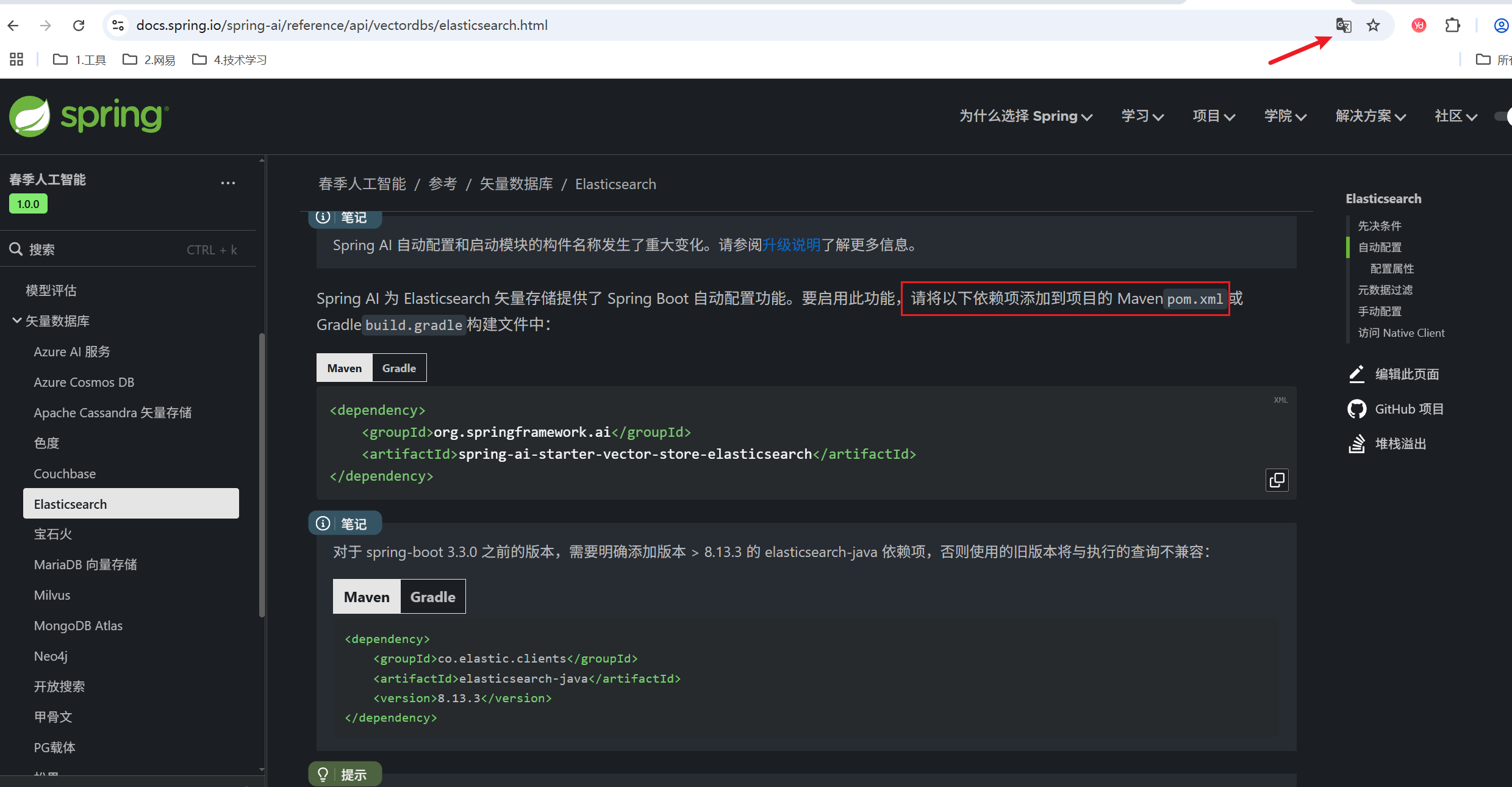
再往下滑,可以看到,文档中明确说了,要连接ES,并使用ES向量数据库,需要在yml文件中做配置
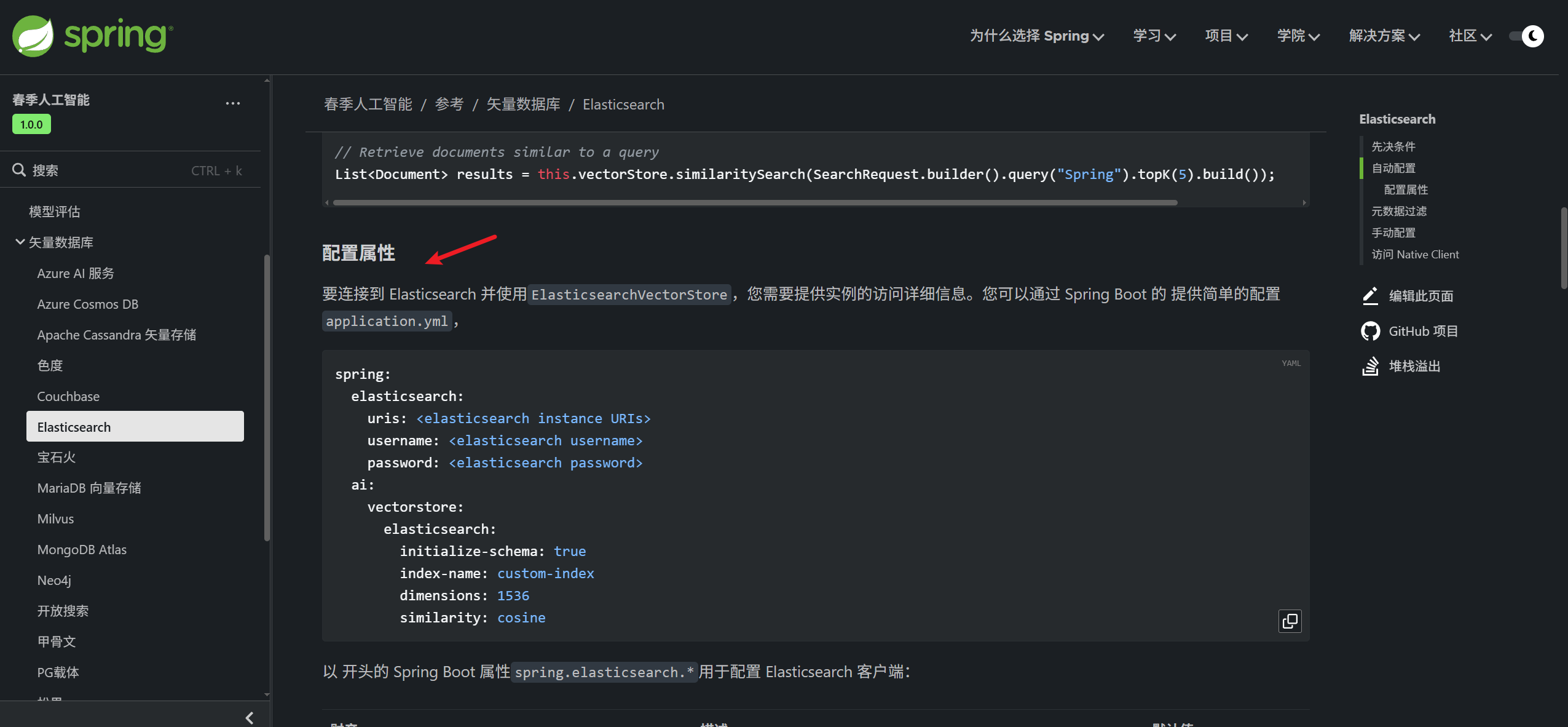
现在pom中加了es的依赖,怎么使用向量数据库呢?文档中明确写了,通过VectorStore 接口与向量数据库进行交互,所有向量数据库都是通过这个接口跟向量数据库进行交互
add:把文本写入向量数据库,文本内容插入向量数据库后,会通过嵌入模型转换为数值数组
similaritySearch:搜索,参数query可以传你要搜索的中文,比如"端午节高速免费吗"
1.3 Simple向量数据库
如果用ES作为向量数据库,那肯定得安装ES,这就有安装的成本了。但是Spring AI提供了一个简单的向量数据库,基于内存的,不需要任何安装,而且文档中也明确说了,适合教育目的
使用Simple向量数据库不需要安装,也不需要在yml文件中配置,只需要创建一个bean,参数是模型,也就是把模型传给向量数据库

1.4 Spring AI读取文档
Spring AI怎么读取pdf、text等文件呢?
点击ETL Pipeline,这是Spring AI提供文件处理的模块
文档中写了The Extract, Transform, and Load (ETL),说明ETL就是3个单词的缩写,其中
Extract:表示提取、拆分的意思
Transform:转化
Load :加载
合在一起就是加载(读取)文档,从文档中提取内容,转化为Document
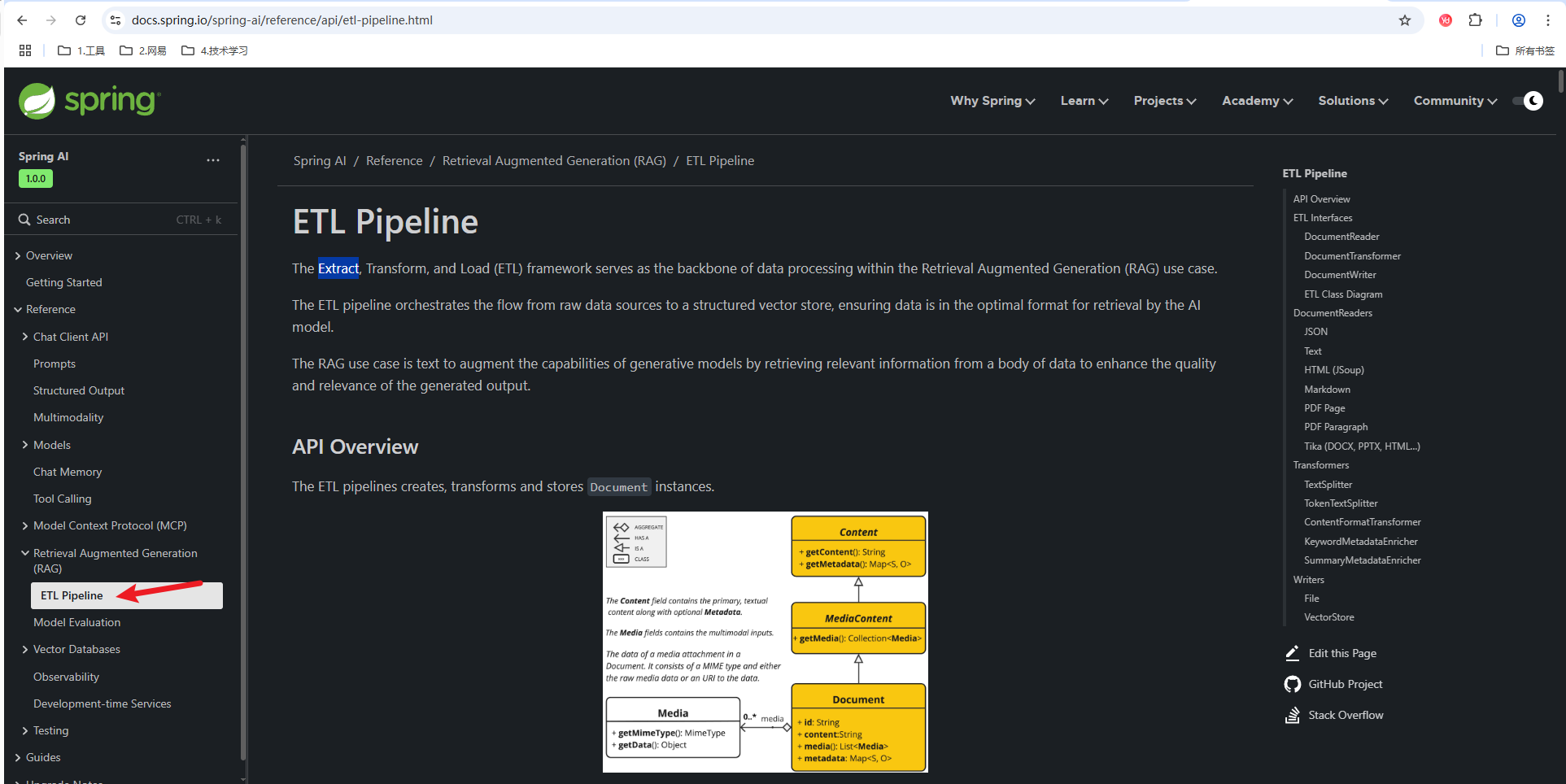
这个图详细介绍了处理文件的过程
1 Document Reader读取源文件,转换成Document
2 Document Transformer转化
3 Document Writer 如何将Document写到数据库里
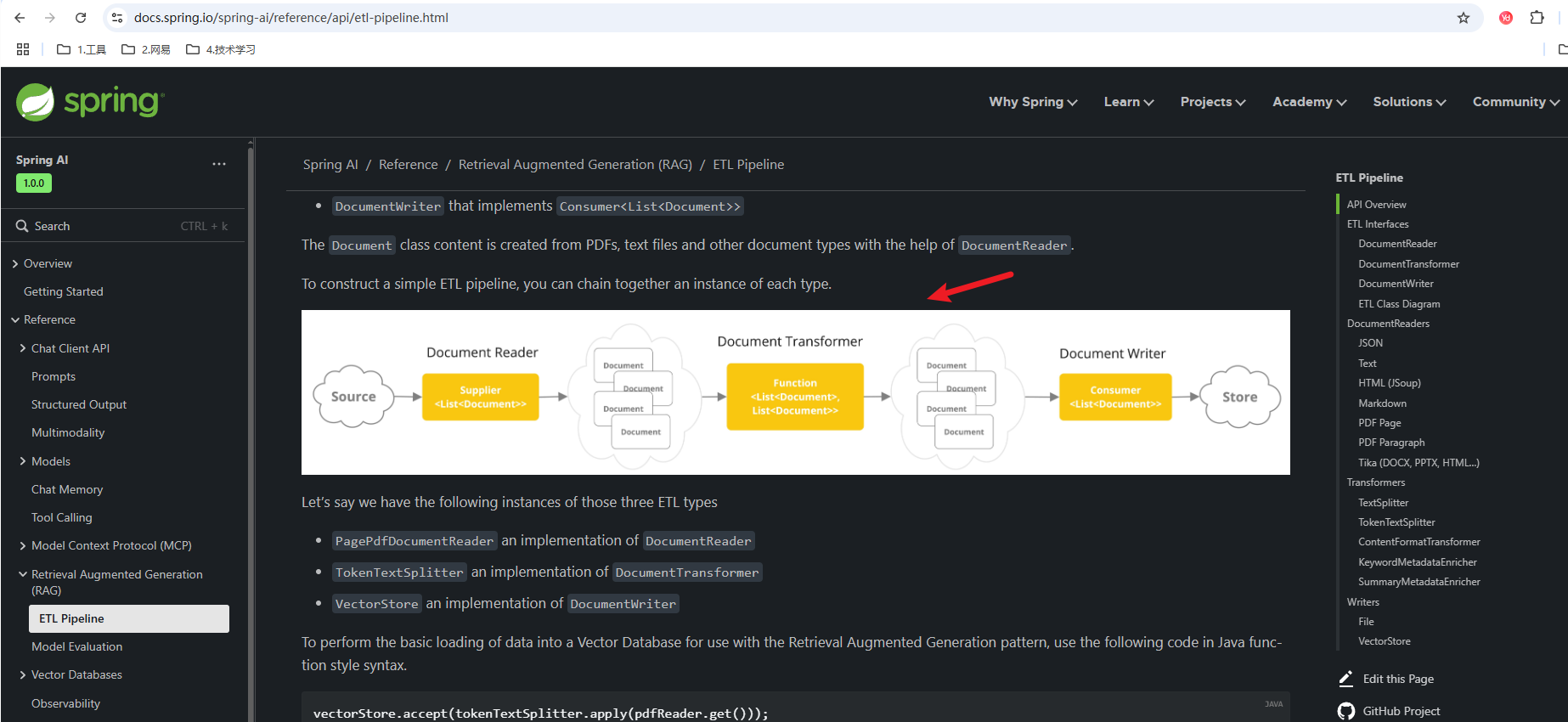
Document Reader有哪些类型呢,或者说Spring AI支持读取哪些类型的文件呢,下图展示的就是支持的文件类型
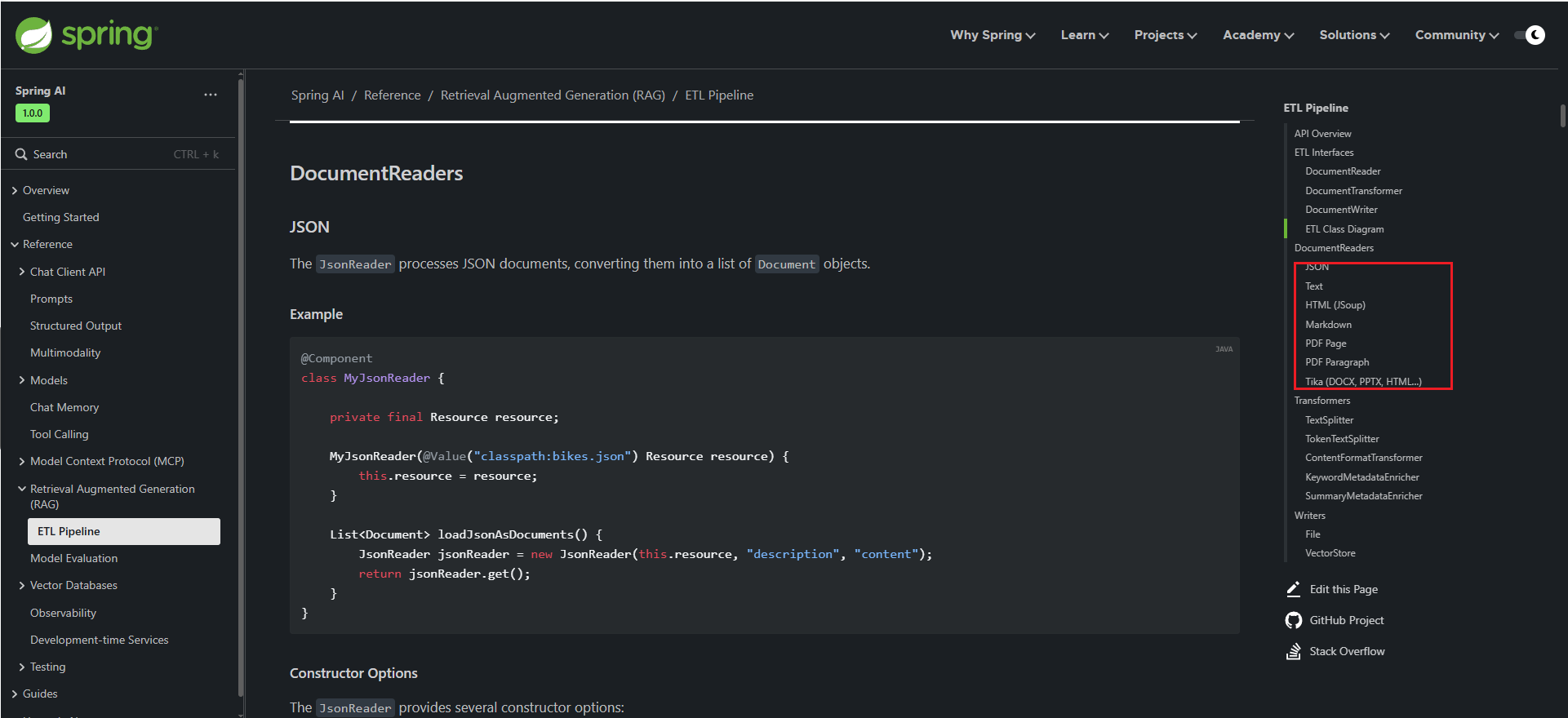
其中 PDF Page和PDF Paragraph分表表示PDF页和PDF段,也就是按PDF页拆分和按PDF段落拆分
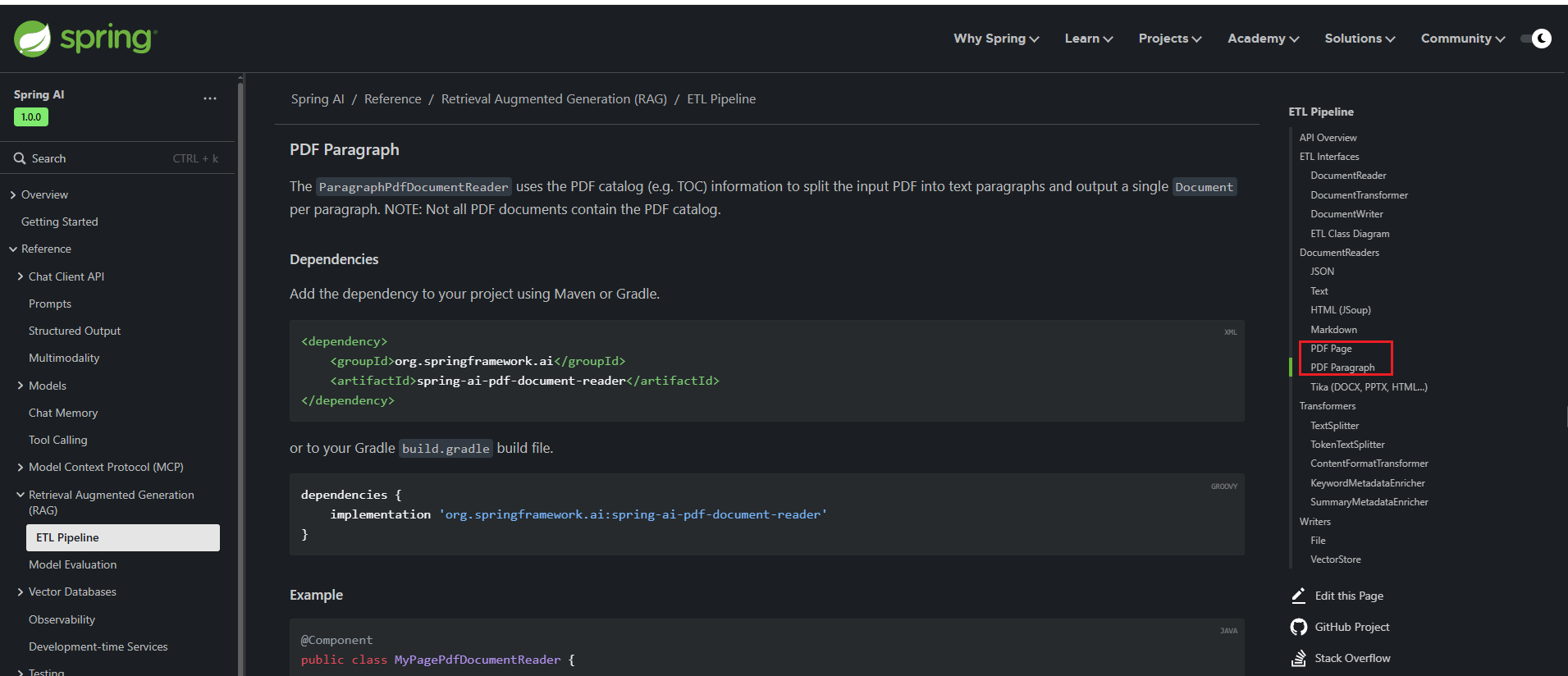
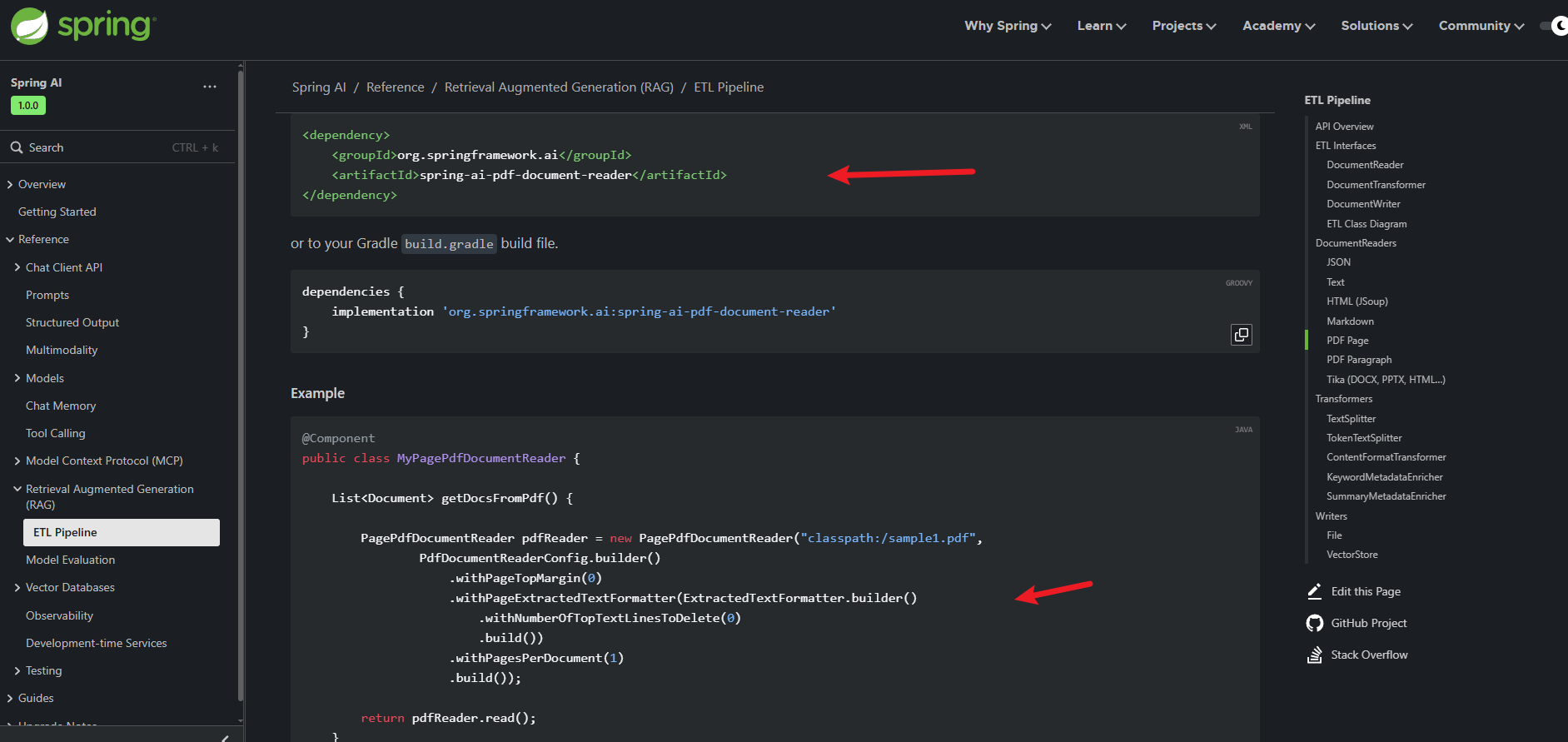
比如PDF按页拆分,怎么做呢?下图所示就是,需要引入什么依赖,怎么把源文件拆分成页去读
1.5 元数据过滤器
比如读取文件的时候,就想读取某个文件,就可以使用元过滤器
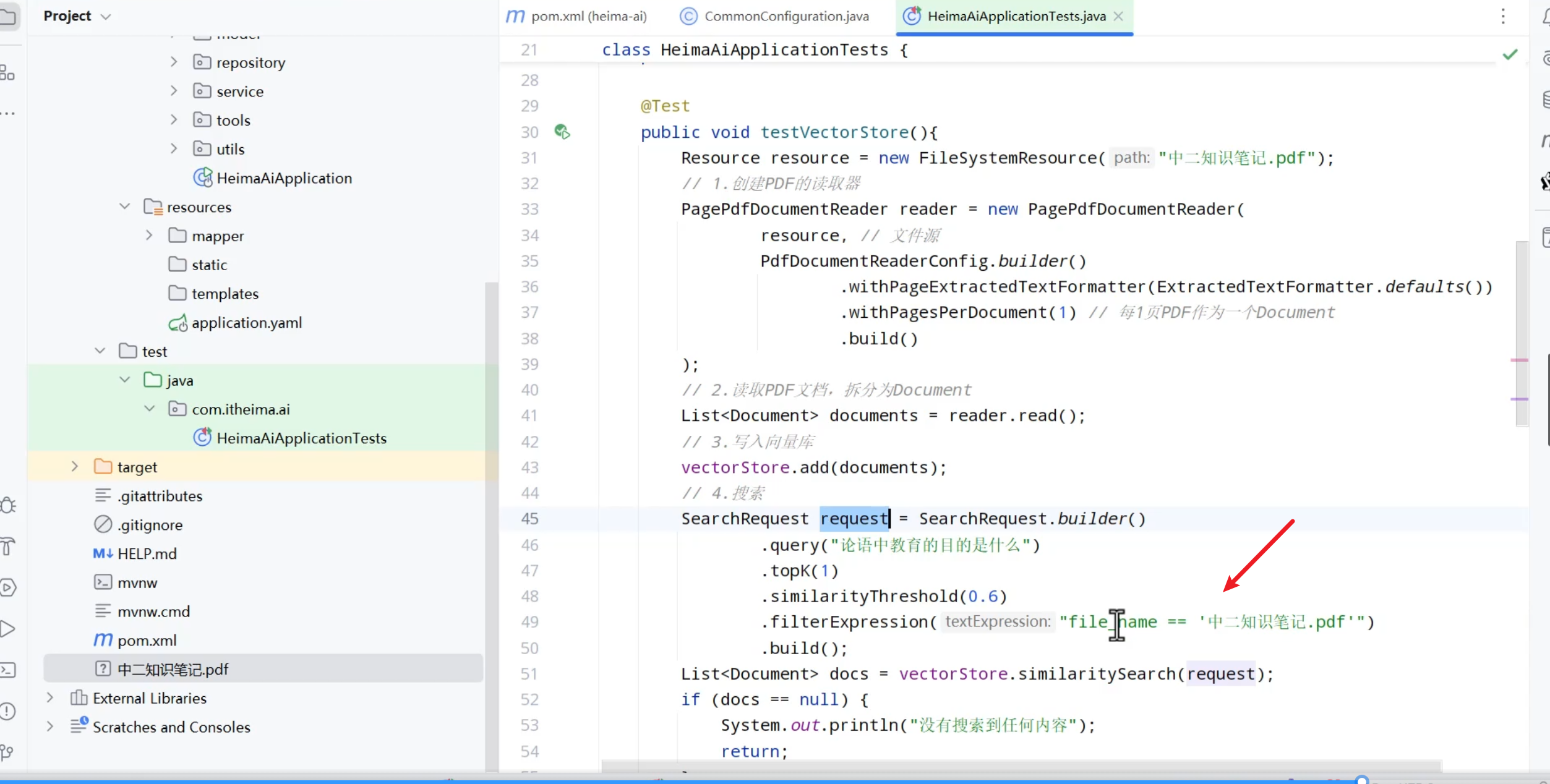
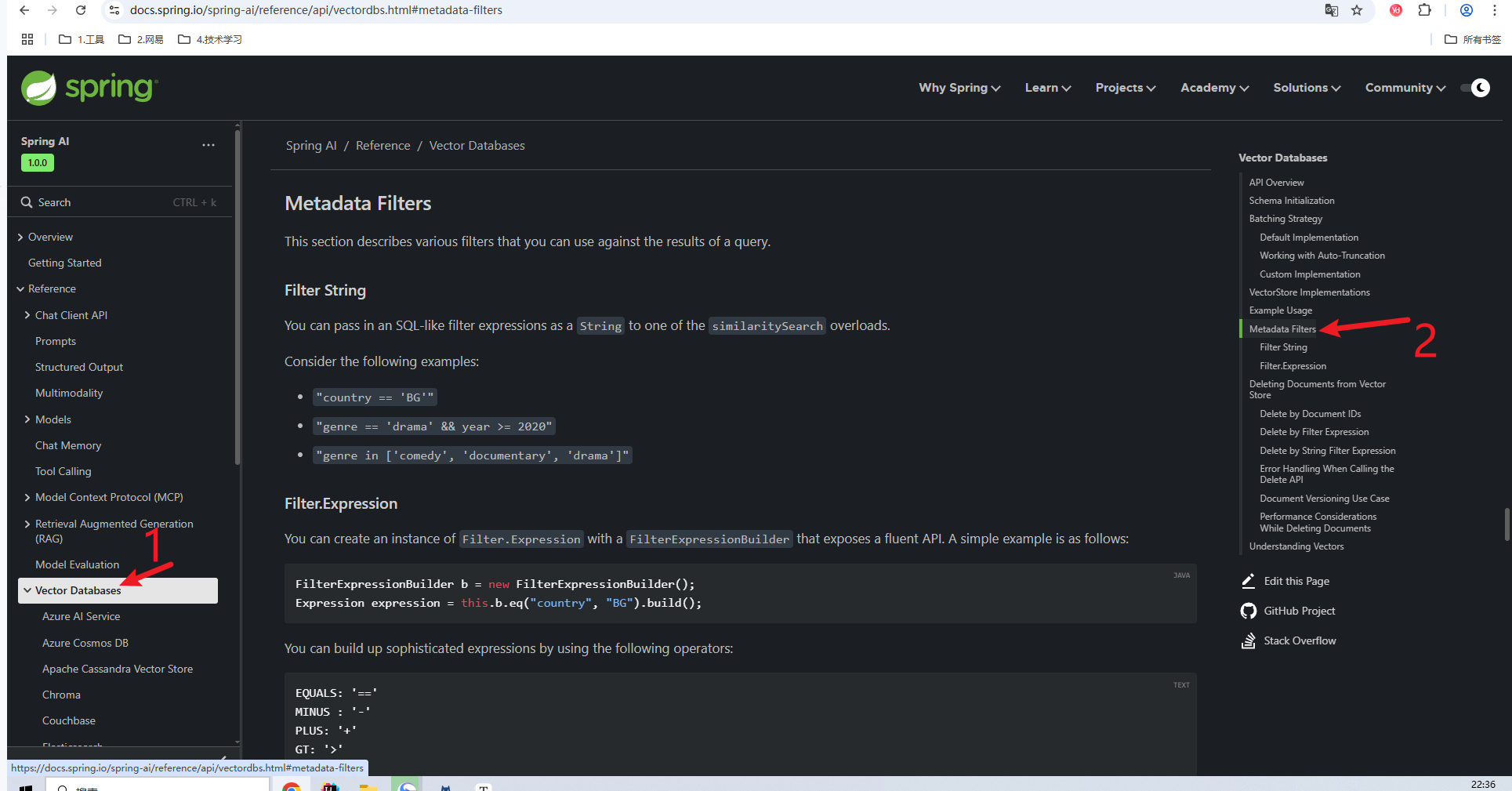
Spring AI官方文档里也有元数据过滤器的介绍
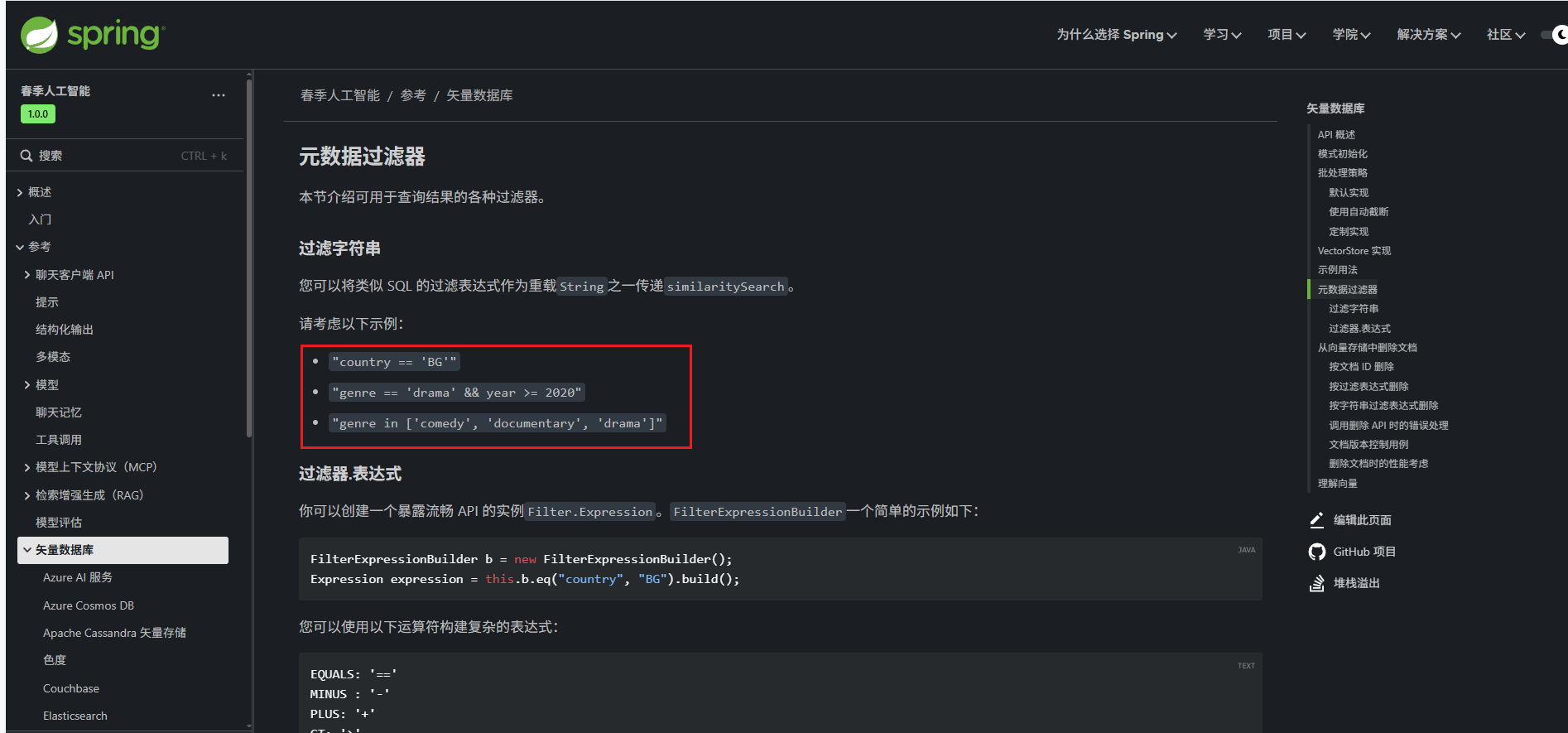
下图就是一些参考示例,比如国家 = BG,年份 > 2020年

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)